



在過去半年,我實際參與了一個中大型系統專案第一期的建置,主要負責 API Gateway 的架構評估與 PoC 驗證。
這件事不只是把服務架起來而已,真正的挑戰在於,要怎麼幫一堆不同性質的服務,設計一個同時兼顧安全性、可觀測性跟高可用性的對外入口。
專案背景與目標
客戶擁有大量內部 API 服務,希望透過數位轉型將其對外開放並商業化。核心目標是建立一個自助式 API 租賃平台,讓開發者能快速申請、按量付費使用,第一期的部份,就是評估方案和架構在正式開發系統前,驗證是否能夠達成需求。
導入前的痛點
| 面向 | 問題 |
|---|---|
| 流程效率 | 紙本申請、多層簽核、綁定 IP,金鑰核發曠日廢時 |
| 用量追蹤 | 無統一監控,不知誰在用、用多少,無法追蹤 |
| 安全穩定 | 缺乏統一認證、無流量控制,難以定位問題 |
| 系統整合 | 子系統各自為政,開發者對接成本高 |
導入後的價值
透過 API Gateway,我們可以帶來的價值:
- 效率提升:API Key 申請從好幾天縮短至幾分鐘
- 透明計費:即時用量統計,支援分級方案設計
- 統一入口:單一 Gateway 存取所有 API,降低學習成本
- 自動化維運:Rate Limiting、ACL 自動運作,集中監控異常
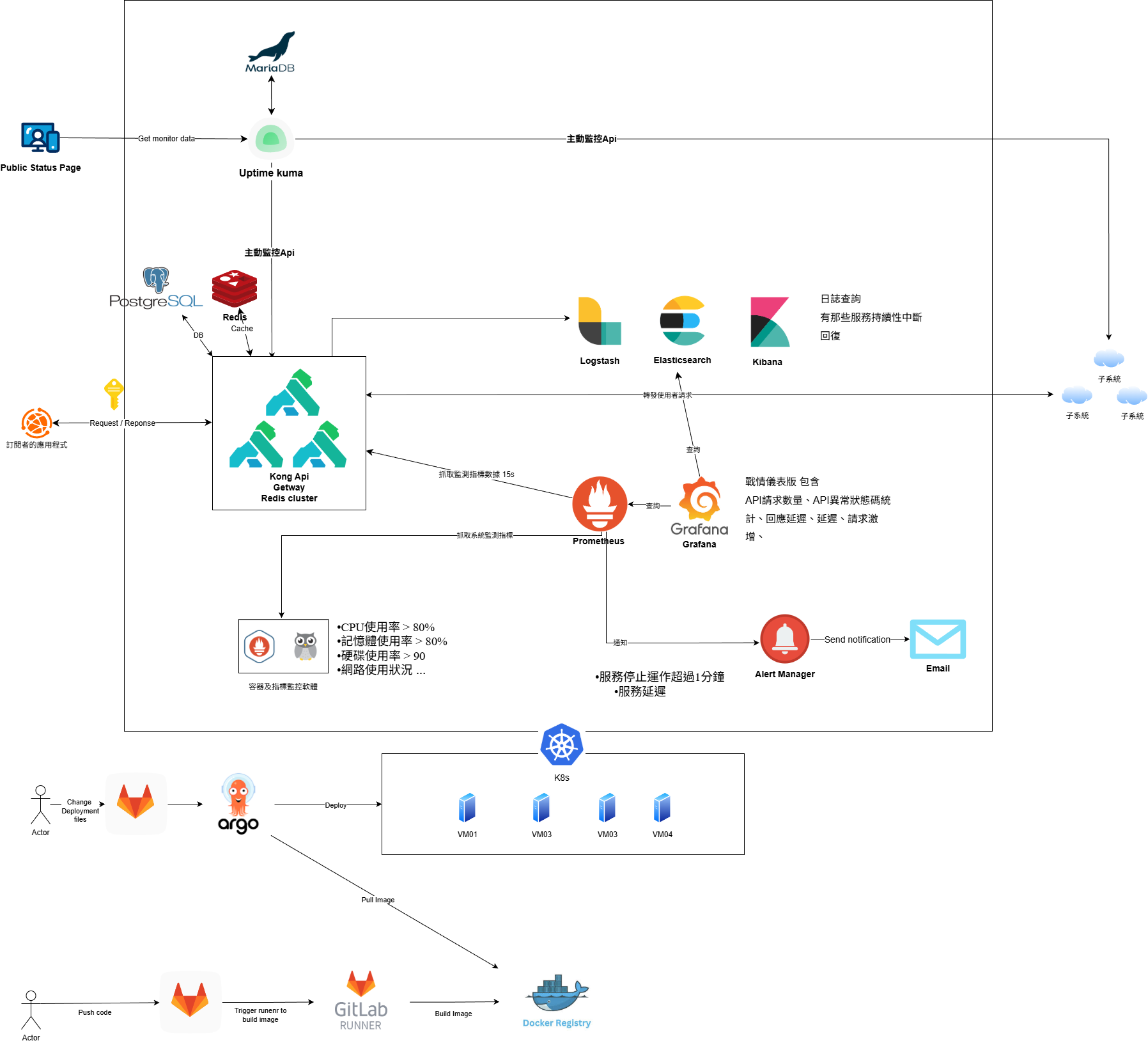
1. 核心架構:為什麼選擇 Kong?
在評估階段,我們需要一個能夠處理高並發請求、支援豐富插件且能與 Kubernetes 原生整合的解決方案,最終我們選用了 Kong API Gateway 搭配 Redis 與 PostgreSQL 作為核心架構。
根據我們的架構規劃:
- 流量入口:所有的外部請求(Request)都由 Kong 統一接管。
- 狀態管理:使用 Redis 處理 Kong 的 Cache 與 Rate Limiting 狀態。
- 配置儲存:使用 PostgreSQL 儲存路由與插件配置,確保資料持久化。
- GitOps 流程:透過 GitLab CI/CD 與 ArgoCD 將設定檔同步至 K8s 環境。
基礎設施環境 (Infrastructure)
這次的架構驗證環境我們選擇部署於 Google Cloud Platform (GCP) 的虛擬機器 (VM) 上,使用 RKE(Rancher Kubernetes Engine) 自行架設 Kubernetes Cluster 進行測試。RKE 是 Rancher 推出的 Kubernetes 安裝與管理工具,主打快速、標準化地在現有主機上部署 Kubernetes 叢集,這讓我們能更彈性地模擬地端機房的網路限制與資源調度情境。
自動化部署策略 (Helm & Helmfile)
我們採用 Helmfile 來管理多個 Helm Releases(包含 Kong, Redis, Postgres 等)。為了讓架構更穩健並符合資安要求,我們採取了狀態分離的部署策略:
- Stateless 服務自動化:Application 層級的元件(如 Kong Gateway, Kuma)完全交由 GitOps 自動同步。
- Stateful 與機敏資料手動化:考量到資料安全性與持久化需求,Secret (敏感資訊) 與 PersistentVolume (PV/PVC) 均從 Helm Chart 中抽離。這些資源由維運人員手動部署 (Manual Apply),確保不會因為 CI/CD pipeline 的誤操作導致資料遺失或金鑰外洩。
效能
依據官方的測試報告Kong Gateway 在單機 16 核心的資源下,能夠穩定處理 10 萬級別的 RPS,且即便在 HTTPS 加密與多重插件邏輯處理下,仍能保持 毫秒級 (Single-digit ms) 的極低延遲,適合對效能有嚴苛要求的微服務架構。
2. API 管理機制的實作 (API Management)
進行 API Gateway 架構驗證的首要目標,是將既有的子系統 API 納入統一管理。
路由與服務配置
我們利用 Kong Manager 進行了標準化的配置工作,重點如下:
-
Gateway Services:統一定義後端服務的轉發目標,涵蓋多種 API 服務協定。
-
突破插件限制 (Plugin Limitation):由於 Kong 的機制限制單一路由無法重複掛載相同類型的插件(例如無法對同一 Route 同時設定兩組不同的 Rate Limiting 規則),我們採用 拆分路由 (Route Splitting) 的策略來解決。針對同一個 Backend Service,依據 URL 特徵拆分出多個 Route,以便分別掛載針對性的流量控制插件,實現更細粒度的管理。
為實作差異化限流,我們採用 Route Splitting 策略。 舉例說明:假設後端有一個電商服務
ecommerce-service,我們可以依據 Route Prefix 拆分成多條路由:Route Name Path Prefix Rate Limit 用途 product-list/api/v1/products/*1000 req/min 商品列表查詢 order-create/api/v1/orders/*100 req/min 訂單建立(高運算) payment-process/api/v1/payments/*50 req/min 金流處理(敏感操作) 透過這種方式,不僅能針對不同 API 設定差異化的流量限制,還能利用 Route Prefix 分別統計各類 API 的用量,便於後續進行用量分析、計費與資源規劃。
-
Routes 與 Rewrite:設定精確的路徑轉發規則。針對舊版 API,我們靈活運用 Request Transformer 插件搭配正規表達式 (Regex) 進行 URI Rewrite(例如將
~/(wms|wmts)/(?<path>api/item/1)$轉發),確保新舊系統能無縫接軌。
💡 這過程中的重要體悟: 進行 API Gateway 架構驗證時,強烈建議優先進行 API 正規化 (Normalization)。 如果後端 API 的 URL 結構混亂、命名不統一,雖然靠 Gateway 的 Regex Rewrite 勉強能轉發,但這會導致路由設定變得極度複雜且難以維護。長痛不如短痛,先梳理好 API 規範,整合起來才會事半功倍。
認證機制選擇:為何採用 Key Auth?
考量使用者組成與相容性,我們在 JWT、HMAC 與 API Key 間權衡後,採用「Header 型 Key Auth」。
- 不選 JWT:需處理過期/刷新與客端狀態,整合與維運成本高。
- 不選 HMAC:必須實作簽章/時戳與加解密,跨語言 SDK 維護成本高。
- 選 Key Auth:低門檻(Header 直接帶金鑰)、高相容(常見工具與框架原生支援)、可疊加安全(IP 白名單、ACL、Rate Limiting)。
使用者呼叫網路服務流程
以下以使用者呼叫流程,概述 Gateway 的實際運作步驟:
- 發起請求:使用者攜帶 API Key 呼叫平台。
- 認證與授權(Kong):驗證 Key 的有效性及權限。
- 流量控制(Rate Limit):檢查是否超過方案額度。
- 服務代理:轉發請求至後端子系統
- 記錄與回傳:非同步寫入 Log,並回傳資料。
分級流量控制 (Tiered Rate Limiting)
為了合理分配運算資源,我們的流量分流策略如下:
- 頻次控制 (Rate Limit):針對一般 API 與高負載服務,分別設定「基礎」與「高頻次」通道,以滿足不同應用場景的需求。
- 頻寬控制 (Bandwidth Limit):針對大檔案傳輸,由於 Kong(即便是付費版)原生並未支援以「流量大小」為基準的精細控制,因此我額外開發了客製化插件來實作頻寬限制。
為了支援多節點 (Multi-Node) 的水平擴展,我們將 Rate Limiting 的策略改為 Redis 模式 (Redis Mode)。所有的計數與狀態皆統一儲存於 Redis 中,確保數據在不同節點間的一致性,避免單機計數導致的誤差。
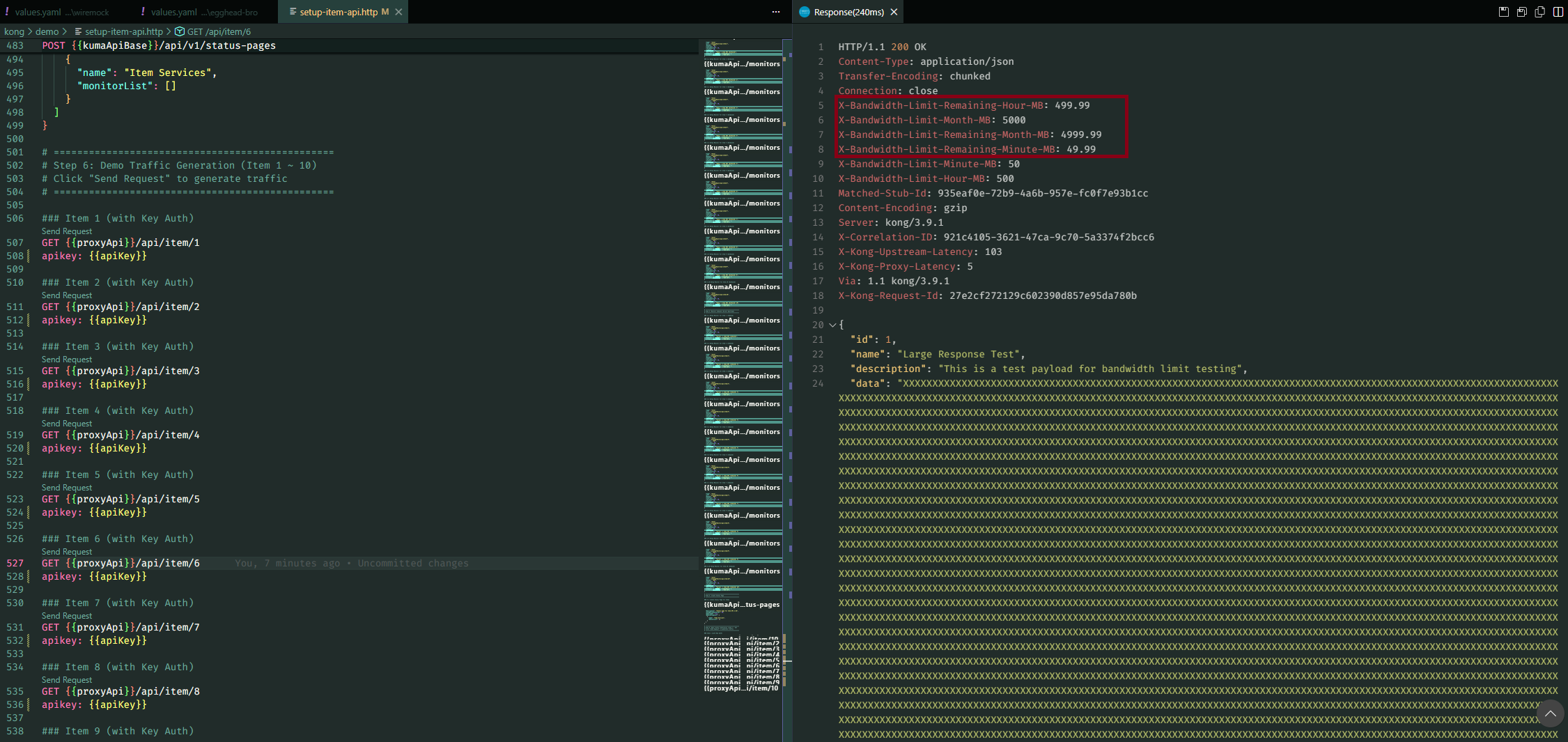
客製化頻寬限制 (Custom Bandwidth Limiting)
除了基礎的請求次數限制 (Rate Limiting),針對大檔案或高頻寬需求的服務,我們開發了客製化的 Kong Lua 插件:
- 多維度頻寬控制:支援從「秒」到「年」的六種時間維度,並自動將 MB 轉換為 Bytes 進行精確運算。
- 高可靠性架構:實作了 Redis 緩存優化與故障轉移 (Fault Tolerance) 機制。當 Redis 發生故障時,插件會自動降級為本地計數策略,防止單點故障影響 API 可用性。
精細的權限管控 (ACL & Consumer Groups)
針對付費與敏感資料,我們利用 ACL (Access Control Lists) 插件建立了嚴格的權限模型:
- 建立了
backend_service,mobile_app等 Consumers。 - 將 Consumer 加入特定群組 (如
business-tier-gold)。
自動化上架流程(基於 Swagger 的 URL Sync)
在解決了核心的路由與權限配置後,下一個挑戰是如何讓眾多子系統快速且標準化地上架。為了避免人工手讀 Swagger 文件再手動 Key 設定所造成的失誤,我們設計了一套 URL Sync 模式。
這套機制的核心在於「規格即時同步」,系統不透過人工上傳檔案,而是直接讀取子系統提供的 Swagger / OpenAPI Specification (OAS) URL。
我們的自動化上架流程包含四個關鍵步驟:
- 規範讀取 (Swagger Sync):管理員只需設定子系統的 Swagger/OAS URL,系統便會自動抓取最新的 API 規格。
- Kong 轉換 (Spec to Config):系統解析 Swagger 內容後,自動在 Kong 內建立對應的 Route 與 Plugin,確保 Gateway 的路由規則與 Swagger 文件定義完全一致。
- 自動監控:上架的同時,系統會自動觸發 Uptime Kuma 建立健康檢查機制(Health Check),實現「服務一上線即監控」的目標。
- 對外發布:完成上述配置後,服務即正式上線並透過 Gateway 進行代理。
3. 打造全方位的監控體系 (Observability)
完善的監控是 Gateway 穩定運行的基石。這半年我們投入了大量心力整合 ELK Stack 與 Prometheus 生態系,實現從「日誌查詢」到「指標儀表板」的全方位可觀測性。
Log 分析 (ELK Stack & Custom Lua)
Kong 的日誌插件本身已包含 client_ip 欄位,但若需要取得更多進階資訊(如經過多層 Proxy 後的原始 IP、X-Forwarded-For Header 等),可以透過 UDP Log 插件的 custom_fields_by_lua 注入客製化欄位:
custom_fields_by_lua = {
remote_addr = "return kong.client.get_forwarded_ip()",
real_ip = "return ngx.var.realip_remote_addr",
x_forwarded_for = "return kong.request.get_header('x-forwarded-for')"
}
這段配置讓我們能取得更完整的來源 IP 資訊,精準分析流量來源與使用行為,對業務決策提供了關鍵數據。同時,我們採用 Sidecar 模式 部署 Filebeat,直接讀取 /var/log/kong 下的 access/error log 並轉發至 Elasticsearch,建立 kong-logs-YYYY.MM.DD 索引。
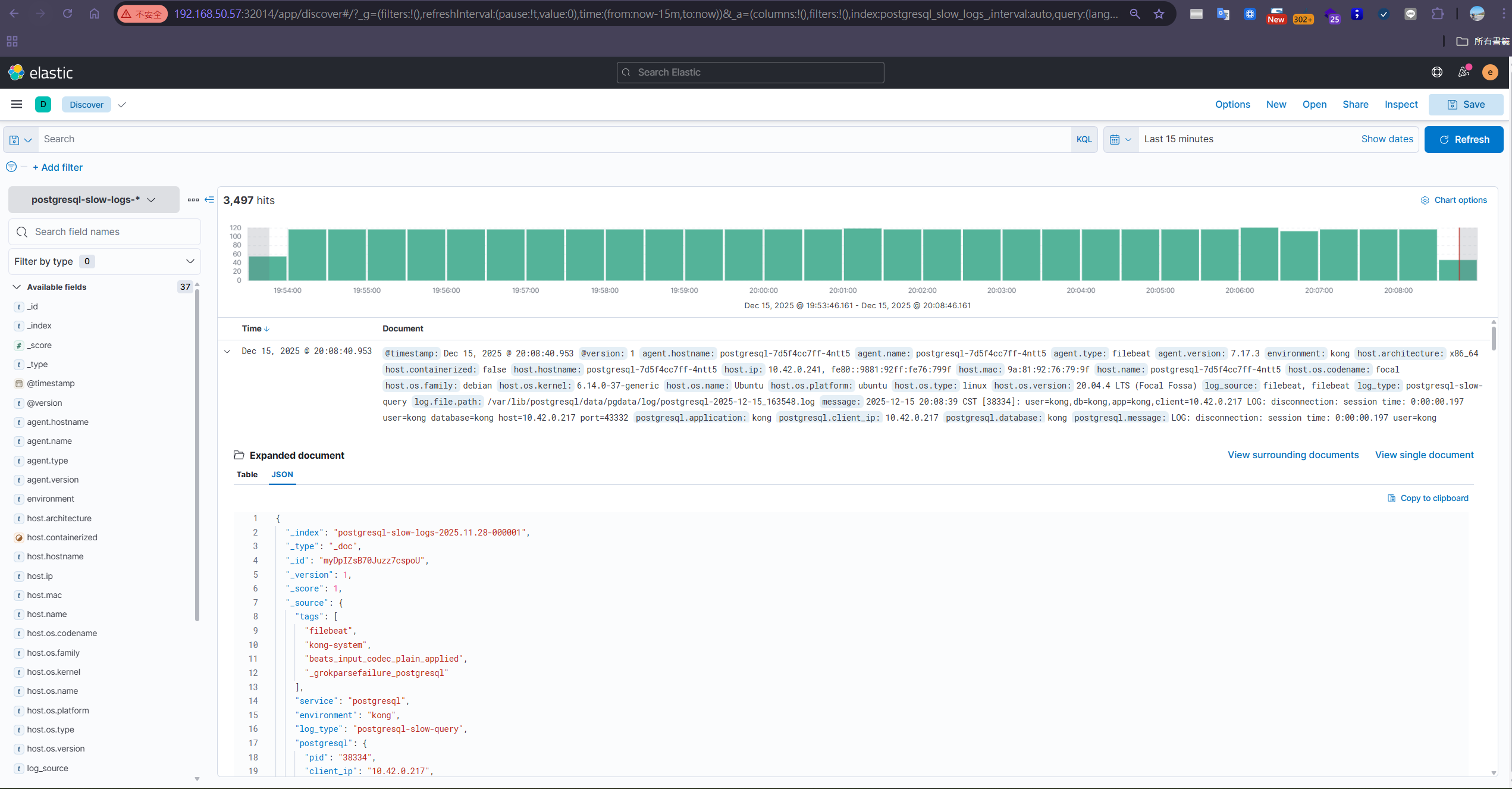
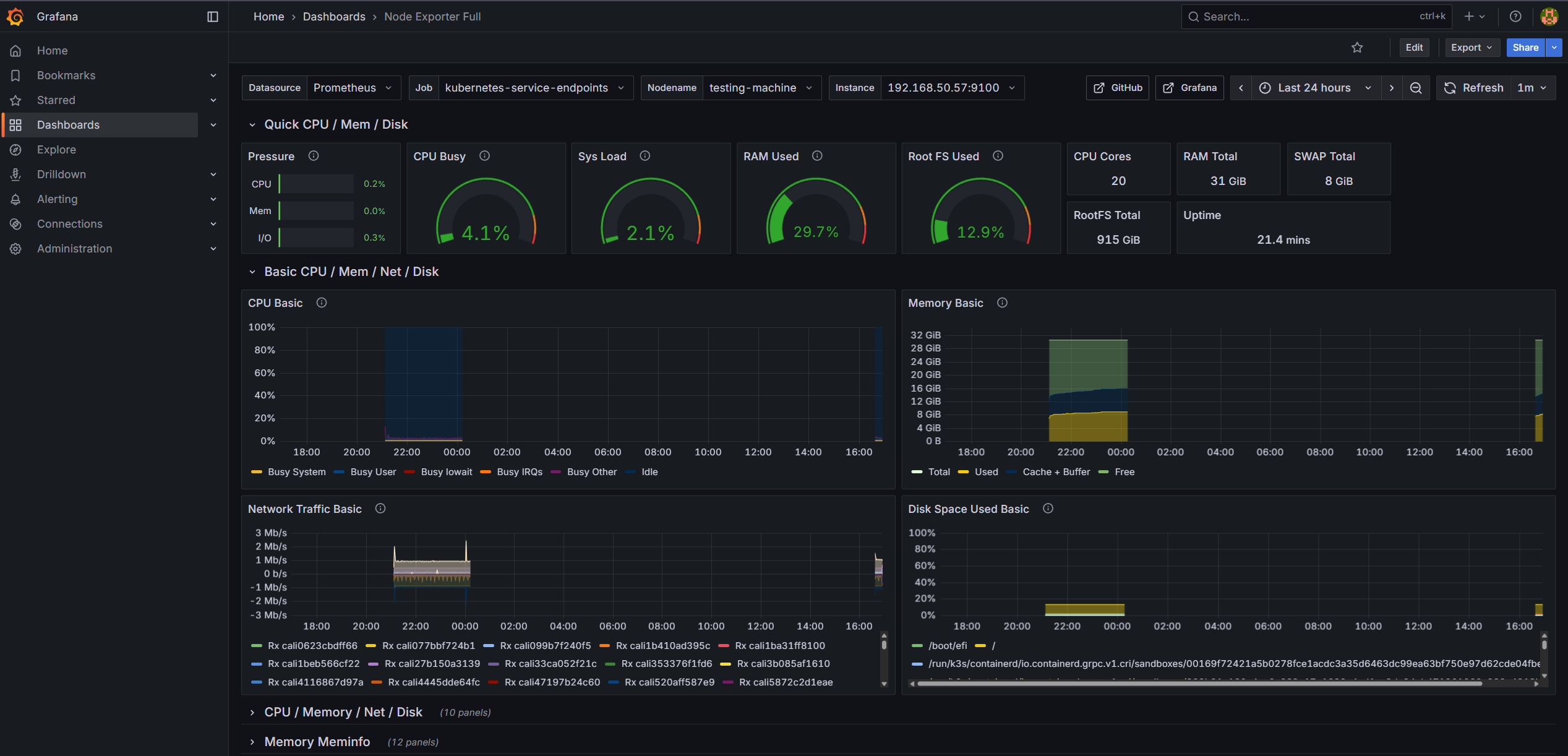
指標監控 (Prometheus & Grafana)
利用 Kong 的 Prometheus 插件,我們收集了詳細的流量指標,並在 Grafana 建立了專屬儀表板:
- Kong API Gateway Dashboard:即時顯示 Request Rate、Latency(延遲)、Bandwidth(頻寬)等關鍵指標。
- Kubernetes Node 硬體監控:透過 Node Exporter 整合,可直接在 Grafana 檢視各 K8s 節點的硬體狀態(CPU、記憶體、Disk I/O、Network Traffic),便於掌握基礎設施的健康度。
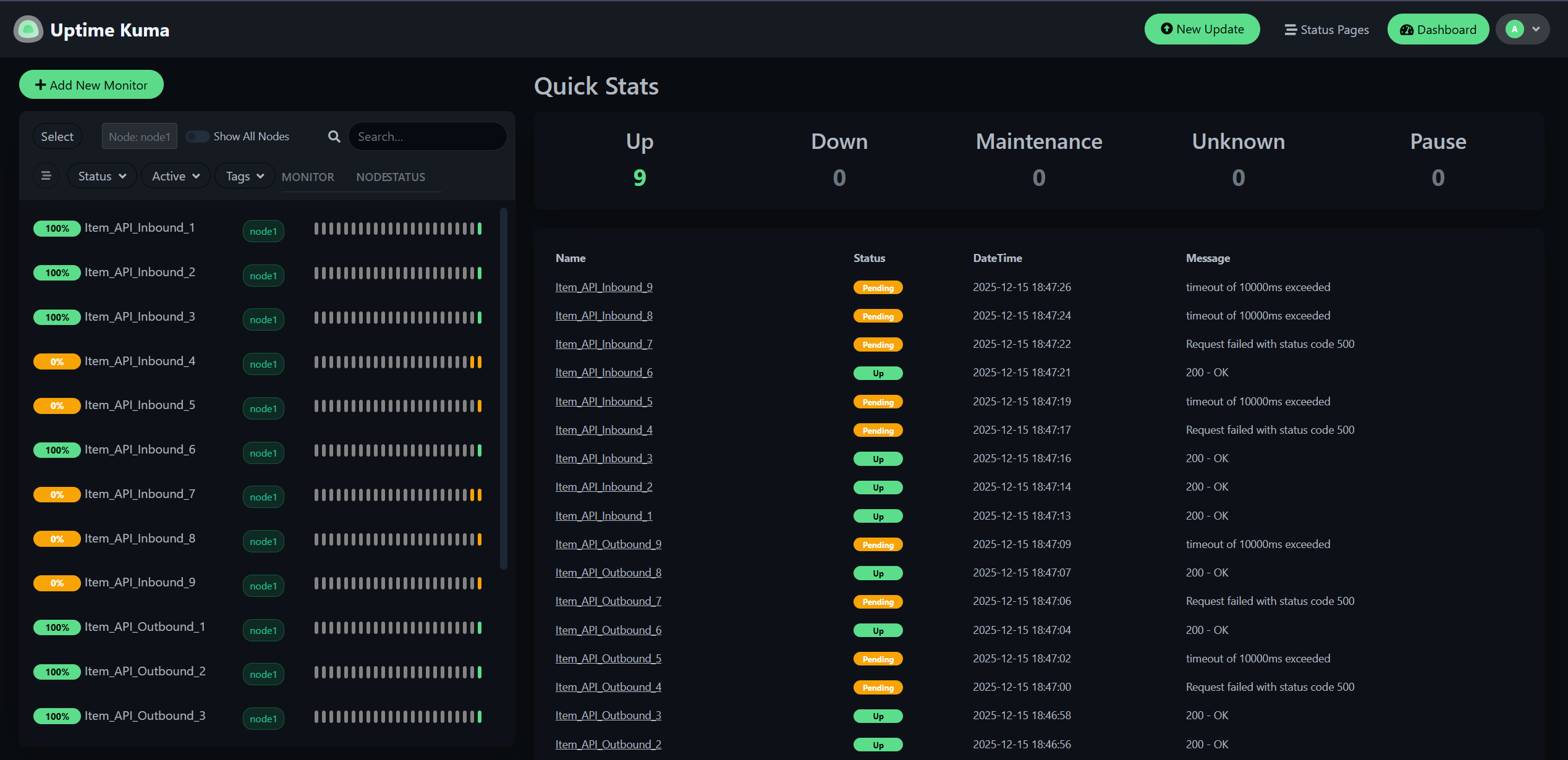
服務可用性監控 (Uptime Kuma Clustering)
Uptime Kuma 是一款開源的自架式監控工具,類似於 Uptime Robot,但可以完全部署在自己的伺服器上。它提供了直覺的 Web UI,支援多種監控類型(HTTP、TCP、Ping、DNS 等),並能透過 Telegram、Slack、Email 等管道發送告警通知。對於需要監控大量內部服務且不想依賴外部 SaaS 的團隊來說,是個很好的選擇。
為了克服原生 Uptime Kuma 在大量監控下的效能瓶頸(約 800 支 API),我們將架構進行了改造:
- 自動化擴充 (RESTful API Extension):由於原生的 Uptime Kuma 缺乏對外的 API 介面,為了實現「服務一上線即監控」的自動化目標,我們自行擴充了 RESTful API 功能,讓日後上架API 時,自動監控。
- Database 抽離:將預設的 SQLite 替換為 MariaDB,並獨立部署為
kuma-mariadb服務,支援更高的併發讀寫。 - Clustering:透過多個 Uptime Kuma 實例連接同一資料庫,實現負載分擔。
關於這部分的實作細節,我另外整理了一篇文章:使用 Vibe Coding 打造 Uptime Kuma 集群系統:從單機到高可用監控平台。
4. 告警機制的建立 (Alerting)
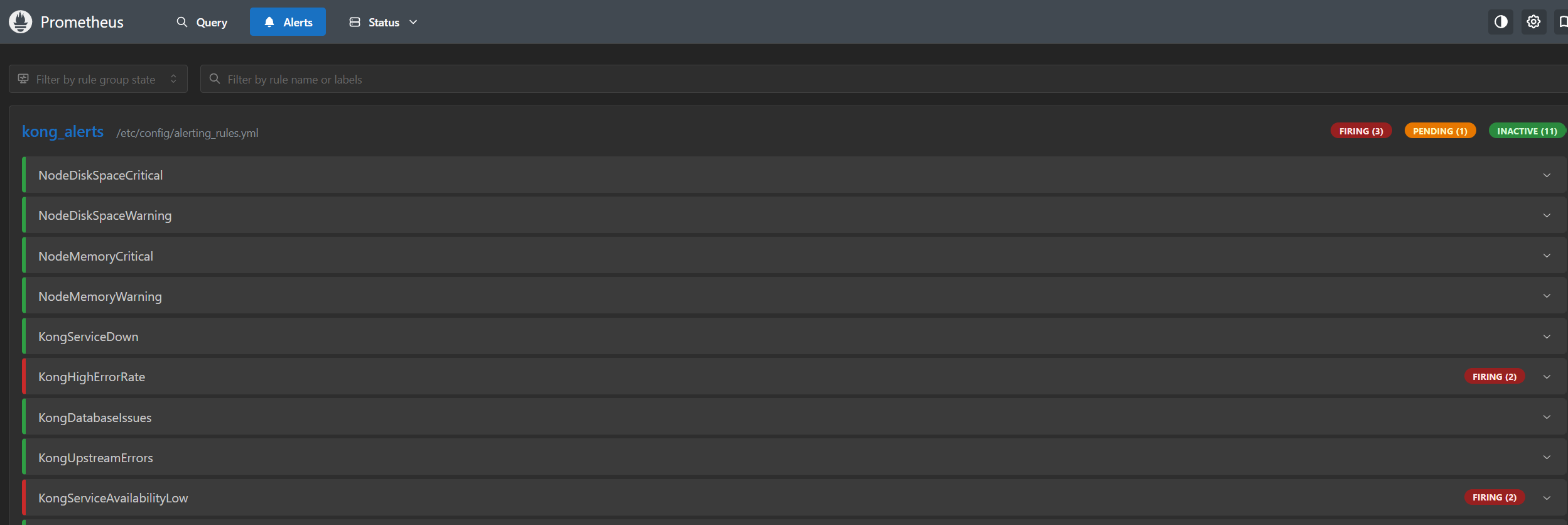

監控的最後一哩路是「告警」。我們在 Prometheus 與 Alert Manager 中定義了 20 條告警規則,分為 Critical、Warning 與 Info 三個等級。
以下是我們定義的幾個關鍵 Critical 告警規則 (PromQL):
1. 服務完全不可用 (KongServiceDown)
當 Kong Namespace 下沒有任何 Up 的 Pod 時觸發:
sum(up{job="kong-metrics", namespace="kong"}) == 0
2. 高錯誤率 (KongHighErrorRate)
當 5xx 錯誤率超過 5% 時觸發,這通常代表後端服務異常:
(sum(rate(kong_http_requests_total{code=~"5.."}[5m])) by (instance)
/
sum(rate(kong_http_requests_total[5m])) by (instance)
) > 0.05
3. 高延遲 (KongHighLatency)
當 P95 請求延遲超過 2 秒時觸發 (Warning 等級):
histogram_quantile(0.95,
sum(rate(kong_latency_bucket[5m])) by (le, instance)
) > 2000
4. 系統資源告警
- 硬碟空間:
NodeDiskSpaceCritical(可用空間 < 5%) - 記憶體:
NodeMemoryCritical(使用率 > 95%)
5. 驗證與成果
這半年的最終成果,順利協助專案通過第一期的系統驗收。
在驗收過程中,我們使用開源 API 測試工具 Hoppscotch (前身為 Postwoman) 針對多項關鍵服務進行了密集的功能驗證。測試結果顯示,API Gateway 不僅能有效攔截未授權的惡意請求,其精細的流量控制機制也能在系統高負載下維持服務穩定,成功達成契約所訂定的各項效能指標。
6. 心得
Kong OSS 本身不提供群組規則、進階流量控管或僅限 route 層級的控制機制,也沒有 API 訂閱的原生概念,因此,若要使用 Kong 來實作 API 訂閱制或較為複雜的群組權限與流量規則,通常需要進行大量客製化;否則在設計上容易顯得不夠貼合需求,必須遷就既有的架構與邏輯。

















留言